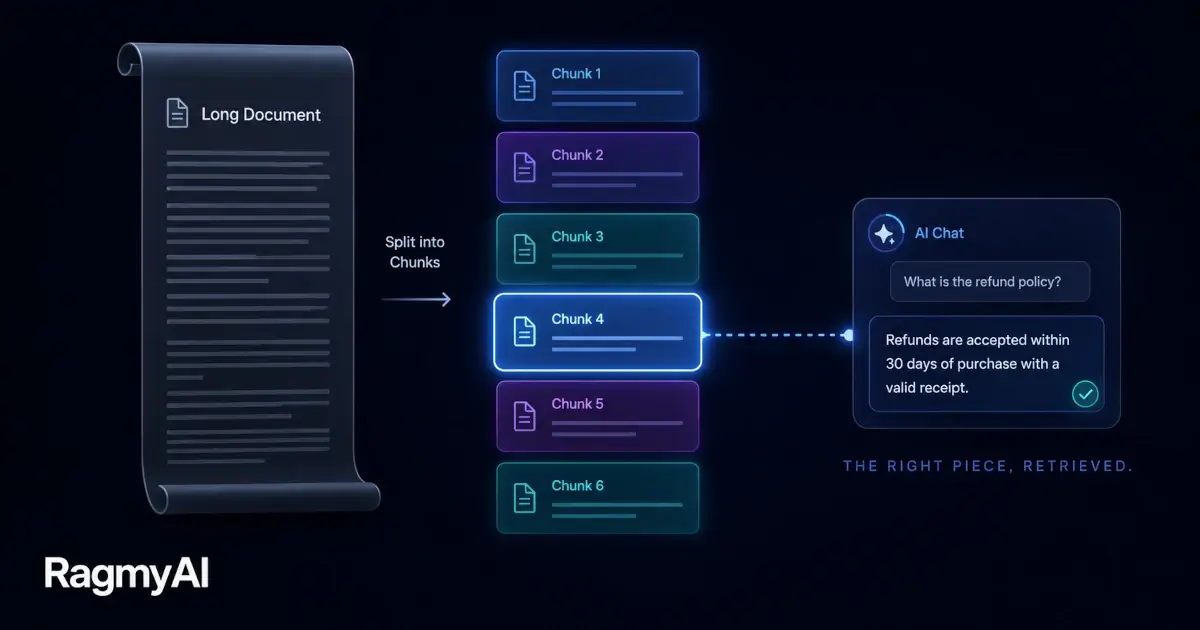
When you upload a document to a RAG system, the first thing that happens is chunking — splitting the document into retrievable pieces. It sounds like a detail. It isn't. Get chunking wrong and no amount of model-tuning will save you.
Why chunking exists
Language models have a context window — a limit on how much text they can process at once. A 200-page contract won't fit. So you break it into passages, embed each one, and retrieve only the relevant ones when a question arrives.
The chunk is the atomic unit of retrieval. If the answer spans two chunks but you only retrieve one, the model sees half the evidence. If a chunk is so long it buries the answer in noise, the model misses it. The right chunk size is small enough to be precise, large enough to be meaningful.
The two mistakes everyone makes
1. Chunking by page
PDFs have page breaks. It's tempting to treat each page as one chunk. Don't. A page boundary in a legal contract might fall mid-sentence, mid-clause, mid-argument. You end up with one chunk that ends "the liability shall not exceed…" and another that starts "…of the total contract value." Neither makes sense alone. Retrieval will fail for any question about liability caps.
2. Chunking too large
Larger chunks retrieve more context, right? In theory. In practice, a 2,000-word chunk retrieved for a narrow question buries the relevant paragraph in three pages of noise. The model's attention spreads thin, confidence drops, and you get hedged, vague answers.
What we do at RagmyAI
RagmyAI splits documents at natural paragraph and heading boundaries, targeting 400–600 words per chunk. We add a small overlap — roughly 50 words — between adjacent chunks so that answers straddling a boundary are still retrievable from either side.
For structured documents like contracts or manuals, we weight the split toward heading boundaries first. A heading almost always signals a topic shift, which makes it a better cut point than an arbitrary word count.
The overlap trick
Overlap is underrated. Imagine the answer is: "The warranty period is 24 months from the date of purchase." If "24 months" falls at the end of chunk 7 and "from the date of purchase" starts chunk 8, a system without overlap retrieves only half the sentence. With a 50-word overlap, both chunks contain the complete sentence. Either one answers correctly.
Practical rules of thumb
- 400–600 words per chunk for general documents. Go narrower (200–300) for highly technical reference material where precision matters more than context.
- Always split at paragraph ends, not mid-sentence or mid-list.
- Add 10–15% overlap between adjacent chunks.
- Never chunk by page. Page boundaries are a print artefact, not a semantic one.
- Re-upload after major edits. Chunks are computed at upload time. If you've revised the document, the old chunks are stale.
When chunking goes wrong — a real example
A university professor uploaded a 90-page lecture series and asked: "What are the three stages of memory consolidation?" The answer was in a table on page 47. Because the system chunked by page, the table header ("Three stages of consolidation") was in one chunk and the table body was split across three others. None of the individual chunks contained a complete answer. The AI improvised — and was wrong.
After re-uploading with paragraph-based chunking, the question was answered correctly on the first try.
Chunking is invisible when it works. When it doesn't, no other part of the pipeline can compensate.