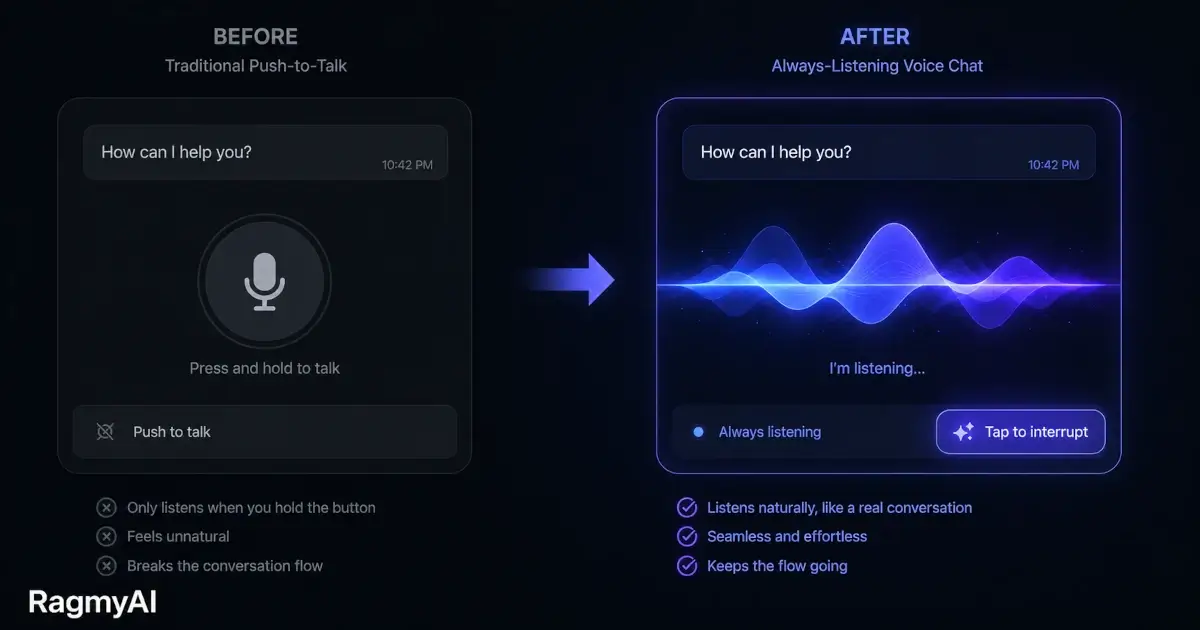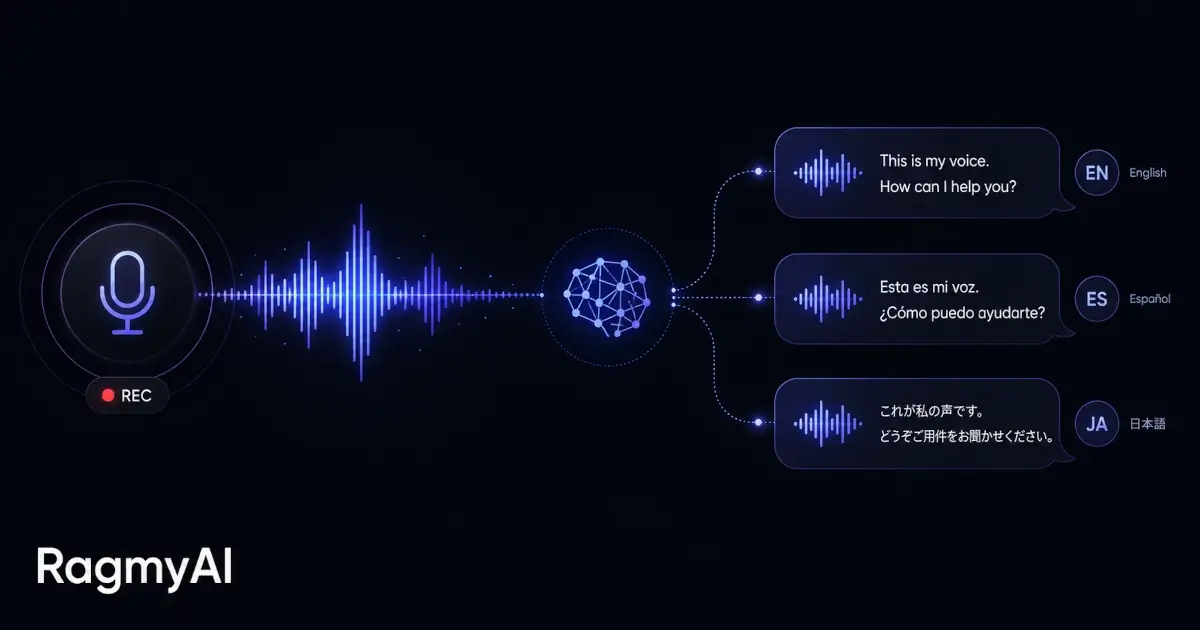
When you record a 60-second voice sample in RagmyAI, you're not giving the model a recording to play back. You're giving it a set of acoustic fingerprints — characteristics it will use to generate entirely new speech, in real time, in any language you ask.
Here's what actually happens.
Step 1: Feature extraction
The model breaks your recording into small overlapping windows — roughly 25ms each — and extracts features from every one: your fundamental frequency (how high or low your voice sits), your formants (the resonances that make vowels sound like vowels), your speaking rate, and your prosody — the rise and fall of pitch that carries emotion and emphasis.
These features are compressed into a speaker embedding: a single vector of numbers that represents your voice. Two recordings of the same person, minutes apart, produce very similar embeddings. A recording of a different person produces a distant one.
Step 2: What 60 seconds gives you
Sixty seconds is enough to capture the key stable features: pitch range, timbre, speaking rhythm, and the specific resonance of your vocal tract. It's not enough to capture every nuance — accent edges, rare phonemes, emotional extremes — but it doesn't need to be. The model fills in the gaps using what it knows about how voices generally work, anchored by your embedding.
Longer samples (3–5 minutes) produce noticeably more accurate clones, especially for accented speech. But 60 seconds gets you 80% of the way there, which is plenty for conversational use.
Step 3: Cross-lingual synthesis
This is the part that surprises most people. Once the model has your speaker embedding, it can generate speech in languages you've never spoken — Spanish, Japanese, Mandarin — in your voice. It does this by decoupling the what (the text content and language) from the who (your voice characteristics). The synthesis model handles both separately, then combines them.
The result isn't perfect — your accent bleeds through, which is actually what makes it sound like you — but it's recognisably yours.
What makes a good recording
- Quiet room, no reverb. Bathroom acoustics add reflections that confuse the feature extractor. A small carpeted room is ideal.
- No background music or TV. The model can partially separate voices, but why make it work harder?
- Speak at your normal conversational pace. Reading unusually slowly skews your prosody features.
- Use a sentence with varied pitch. Monotone recordings produce flat-sounding clones. Read something with natural question and answer structure.
- Phone mic is fine. You don't need a studio microphone. Holding the phone 15–20cm from your mouth, at a slight angle, avoids plosive pops and works well.
What the model cannot learn from 60 seconds
Whispers, shouts, and emotional extremes (crying, laughing) require separate samples because they activate different parts of the vocal mechanism. If you ask the cloned voice to express strong anger, it will approximate it from your neutral prosody — which sounds unconvincing. For most use cases — answering questions, explaining documents, giving instructions — this limitation doesn't matter at all.
The clone also can't reproduce speech disorders or highly idiosyncratic phoneme pronunciations that fall outside the model's training distribution. It rounds to the nearest thing it knows how to make.
Privacy note
Your voice sample is processed on upload, the embedding is stored, and the raw audio is deleted. The embedding itself is not useful for reconstructing your original recording — it's a compressed mathematical representation, not a copy of the audio file. It is, however, enough to generate new speech that sounds like you, so treat it like a password in terms of who you share access with.